The client partnered with ULG to determine what methods of translation would best fit each content need and ensure accuracy of the output. ULG created a customized technology and translation plan to achieve the following:
- Maintaining compliance with industry regulations.
- Streamlining internal communication among its global workforce
- Reducing costs for non-critical content
- Decreasing time to market
ULG determined the utilization of Neural Machine Translation (NMT) would help the client achieve the increased speed it required.
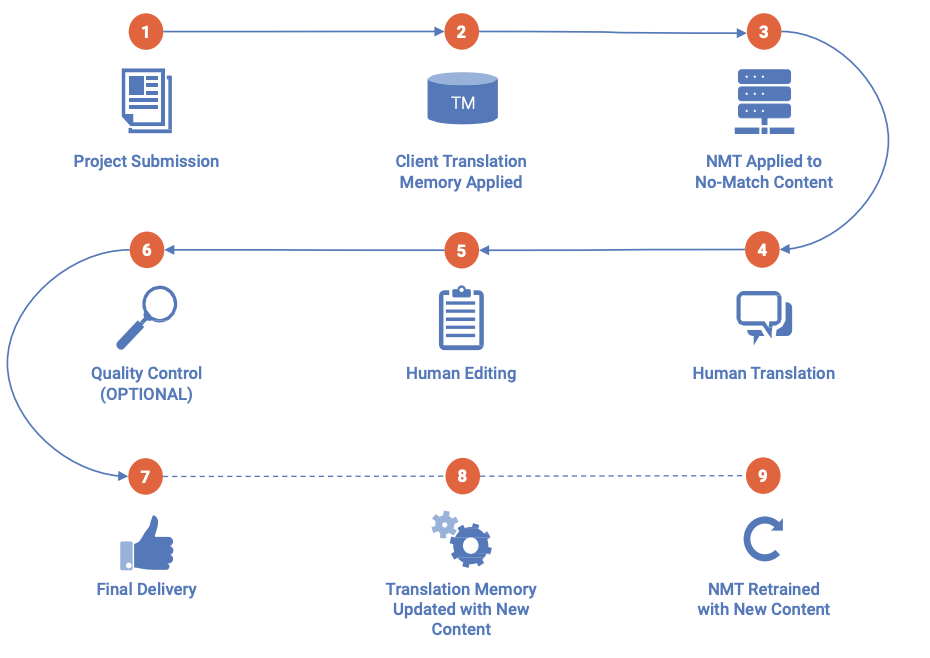
To maintain the quality, ULG was able to build a client-specific mix of human and machine translation that would ensure consistency and accuracy across languages.
For the content that needed to meet the steep regulatory and quality requirements, ULG implemented a combined machine translation, human translation and human editing solution. This unique blend effectively reduced costs by using a seamless workflow integrated with a customized NMT solution that opened the door to greater efficiencies.
The workflow ULG built was similar to the below: